Empirical Risk Minimization with Inductive Bias
In this section, we formal prove that we are able to avoid overfitting by
-
Limiting the number of possible hypothesis and
-
Increasing the number of training data.
Finite Hypothesis Class
-
A common solution to avoid overfitting is to restrict the search space of ERM
-
Formally, the learner should choose in advance (before seeing the data) a set of predictors
, called a hypothesis class
-
For a given hypothesis class
, the
learner choose a predictor
, with the lowest possible error over
-
By restricting the learner to choosing a predictor from
, we bias it toward a particular set of predictors. Such restrictions are often called an inductive bias
-
The restriction is determined before the learner sees the training data, it should ideally be based on some prior knowledge about the problem to be learned
-
For example, for the papaya taste prediction problem we may choose the class
-
A fundamental question in learning theory is, over which hypothesis classes, will
not result in overfitting
-
Intuitively, choosing a more restricted hypothesis class better protects us against overfitting but at the same time might cause us a stronger inductive bias
Derivation of Learning Ability
In the following, we will prove that we are able to avoid overfitting by having finite hypothesis claas and sufficiently large training sample. The overview of the proof is as follows:
-
We write down the probability of overfitting and set an inequality equation to upper bound on it
-
By solving the inequality equation, we derive the number of samples required to avoid overfitting at certain confidence level
We will have two assumptions for the following derivation:
-
The Realizability Assumption: There exists
. That is, we can always find a hypothesis in
-
The i.i.d. Assumption: The examples in the training set are independently and identically distributed (i.i.d.) according to the distribution
. We denote this assumption by
[1]
Note that the first assumptions implies can always find a hypothesis that leads to zero empirical risk. However, since there might be multiple hypothesis that leads to zero empirical risk,
is not guaranteed to be selected. Therefore, we will not face underfitting (training error too high) but we are still at the risk of overfitting.
We will also utilized two lemma:
-
Union Bound: For any two sets
and a distribution
-
, Proof:
Derivation of The Inequality
-
gives us a hypothesis
.
-
We interpret the event that the true error is greater than a certain amount as overfitting
-
Since
depends on the training set
-
We than upper bound the probability of overfitting with a parameter
such that
, whereis the instances of the training set
In other words, overfitting happens when we are unlucky to get a non-representative sample that leads to great true error. What we want to do is to bound the probability of such "unluckiness" to a small value .
Derivation of the Result
To derive the upper bound of , we first analyze the "bad sample" set
.
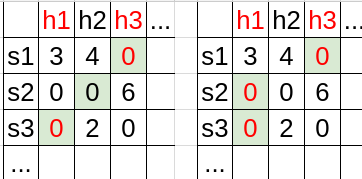
In the following image, we order all hypothesis and sample sequentially. Each cell records the empirical risk . Though the true error is not shown, each "bad" hypothesis
such that
are highlighted in red color. The cells highlighted in light green records which hypothesis
selects for each sample. Overfitting happens when a bad hypothesis is selected (text highlighted in red color).
The two table shows two possible , selecting different hypothesis for each sample. For the left case,
and
are "bad" samples. As for the right case, all
and
are "bad" samples.
Clearly, the "bad" sample set depends on how
selects the hypothesis
for each sample. However, we could see that a sample is a potential "bad" sample if one of the "bad" hypothesis achieves zero empirical risk on it.
Formally, we define the set of "bad hypothesis"
, and the set of "potential bad samples":
It follows that, and
could be rewritten as:
Hence, the overfitting probability is now bounded by:
By the union bound lemma, we have
By the i.i.d assumption
For each individual sampling of an element of the training set we have
The last inequality holds bacause we are considering hypothesis , and by definition, each of these "bad" hypothesis satisfies that
.
By the lemma , we have
Finally, we get the upper bound of the overfitting probability:
To be more clear,
Since we want the overfitting probability be bounded by , we then solve:
And this leads to:
COROLLARY 2.3
Let be a finite hypothesis class. Let
and
and let
be an integer that satisfies
Then, for any labeling function, , and for any distribution,
, for which the realizability assumption holds (that is, for some
holds), with probability of at least
over the choice of an i.i.d. sample
of size
, we have that for every ERM hypothesis,
, it holds that
The preceding corollary tells us that for a sufficiently large , the
rule over a finite hypothesis class will be probably (with confidence
) approximately (up to an error of
) correct.
A Final Analogy
Imageine that you are hosting a company and you are hiring workers from a finite pool (). Each of your customer will order a list of
-tasks to execute (
-tuple sample
). To complete the order, you simply choose one worker form those who make no error for all the tasks on the list (ERM).
Though things went well, one day, you just come up the the question that whether you are hiring the right person. You suspect that the worker you choose might do well for the order list, but he/she might fail on many other tasks. You feel that is unfair for those left good workers who performe well not only for the order list but also for the other tasks.
You then remember that the machine learning theory teaches you a lesson. All you need to do is to combine several order lists into a new one such that the new one contains much more tasks. The intuition is that if the worker does not really perform well on many tasks (true error ), as you increase the number of tasks on the list, he/she becomes less likely to make no error for tasks on the list and hence will not be chosen by you. By doing so, with a certain confidence level, you know that the workers you chose not only perform well for customer orders but they also make little error when asked to execute the other tasks.
1. Like ) ,
, ) assigns a probability determining how likely it is to observe a sequence of sample belonging to the event
assigns a probability determining how likely it is to observe a sequence of sample belonging to the event 